Thuật toán A* (A-star) là một thuật toán tìm đường sử dụng trong các lĩnh vực như trí tuệ nhân tạo, đồ họa máy tính, và robot học. Nó được sử dụng để tìm đường đi ngắn nhất từ điểm khởi đầu đến điểm đích trên một đồ thị.
Thuật toán A* kết hợp hai yếu tố chính:
1. Giá trị chi phí đi từ điểm khởi đầu đến điểm hiện tại (g(n)).
2. Ước lượng chi phí từ điểm hiện tại đến đích (h(n)), còn gọi là hàm heuristic.
Tổng chi phí của một nút n được tính bằng công thức:
f(n) = g(n) + h(n)
Trong đó:
- g(n) là chi phí từ điểm khởi đầu đến nút n.
- h(n) là chi phí ước lượng từ nút n đến đích (hàm heuristic).
Thuật toán A* hoạt động bằng cách khám phá các nút với giá trị f(n) nhỏ nhất trước, đảm bảo rằng nó tìm ra con đường ngắn nhất nếu hàm heuristic h(n) là admissible (không bao giờ đánh giá quá cao chi phí từ n đến đích).
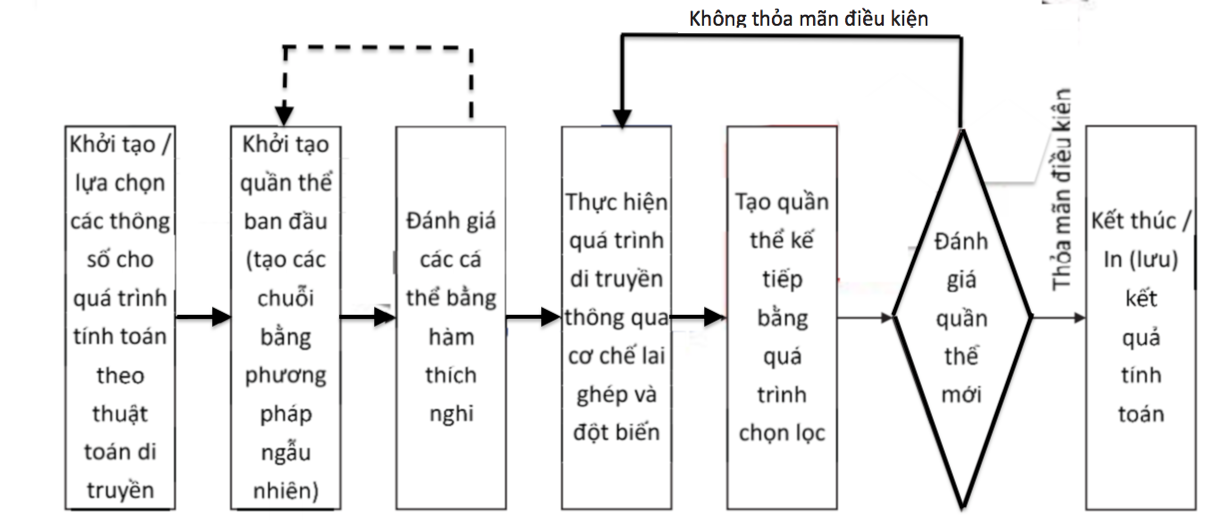
### Sơ đồ thuật toán A*
1. Khởi tạo:
- Tạo danh sách mở (open list) và thêm nút bắt đầu vào danh sách này. Khởi tạo danh sách đóng (closed list) rỗng.
- Đặt giá trị g(n) của nút bắt đầu là 0 và f(n) = g(n) + h(n).
2. Lặp lại các bước sau cho đến khi danh sách mở trống hoặc tìm thấy điểm đích:
- Chọn nút có giá trị f(n) nhỏ nhất trong danh sách mở và gán nó là nút hiện tại.
- Nếu nút hiện tại là đích, tái tạo đường đi từ điểm khởi đầu đến điểm đích và kết thúc.
- Di chuyển nút hiện tại từ danh sách mở sang danh sách đóng.
- Đối với mỗi hàng xóm của nút hiện tại:
+ Nếu hàng xóm nằm trong danh sách đóng, bỏ qua nó.
+ Nếu hàng xóm không nằm trong danh sách mở, thêm nó vào danh sách mở và tính các giá trị g(n), h(n), và f(n).
+ Nếu hàng xóm đã nằm trong danh sách mở, kiểm tra xem đường đi hiện tại đến hàng xóm có tốt hơn không. Nếu có, cập nhật giá trị g(n), h(n) và f(n) của hàng xóm và cập nhật nút cha.
3. Kết thúc:
- Nếu danh sách mở trống và điểm đích không được tìm thấy, báo rằng không có đường đi.
### Mô tả step-by-step các bước
1. Initialization (Khởi tạo):
- Đặt nút bắt đầu (start) vào danh sách mở (open list).
- Thiết lập g_score của nút bắt đầu là 0.
- Tính toán f_score của nút bắt đầu bằng cách cộng g_score và heuristic (h(n)).
2. Loop until the open list is empty or the destination is found (Lặp lại cho đến khi danh sách mở trống hoặc tìm thấy đích):
- Step 1: Chọn nút có giá trị f(n) nhỏ nhất trong danh sách mở (gọi là nút hiện tại).
- Step 2: Nếu nút hiện tại là điểm đích, tái tạo và trả về đường đi.
- Step 3: Di chuyển nút hiện tại từ danh sách mở sang danh sách đóng.
- Step 4: Đối với mỗi hàng xóm của nút hiện tại:
+ Step 4.1: Nếu hàng xóm nằm trong danh sách đóng, bỏ qua nó.
+ Step 4.2: Tính g_score tạm thời (tentative_g_score) cho hàng xóm.
+ Step 4.3: Nếu hàng xóm không nằm trong danh sách mở hoặc tentative_g_score nhỏ hơn g_score hiện tại của hàng xóm:
Cập nhật nút cha của hàng xóm là nút hiện tại.
Cập nhật g_score và f_score của hàng xóm.
Nếu hàng xóm không nằm trong danh sách mở, thêm nó vào danh sách mở.
3. ermination (Kết thúc):
- Nếu danh sách mở trống và điểm đích không được tìm thấy, báo rằng không có đường đi.
### Ví dụ cụ thể
Giả sử chúng ta có một đồ thị đơn giản:
- Bắt đầu tại A, cần tìm đường ngắn nhất đến F.
- Hàm heuristic sử dụng khoảng cách Manhattan.
**Step-by-step:**
1. Initialization:
- Đặt A vào danh sách mở. g(A) = 0, h(A) = heuristic(A, F), f(A) = g(A) + h(A).
2. Loop:
Iteration 1:
- Chọn A (f(A) = 0 + h(A)).
- Di chuyển A từ danh sách mở sang danh sách đóng.
- Xem xét các hàng xóm của A: B, C.
+ Với B: tentative_g(B) = g(A) + 1 = 1. Đặt g(B) = 1, h(B), f(B) = g(B) + h(B).
+ Với C: tentative_g(C) = g(A) + 4 = 4. Đặt g(C) = 4, h(C), f(C) = g(C) + h(C).
- Thêm B và C vào danh sách mở.
Iteration 2:
- Chọn B (vì f(B) nhỏ hơn f(C)).
- Di chuyển B từ danh sách mở sang danh sách đóng.
- Xem xét các hàng xóm của B: A, D, E.
+ Với D: tentative_g(D) = g(B) + 2 = 3. Đặt g(D) = 3, h(D), f(D) = g(D) + h(D).
+ Với E: tentative_g(E) = g(B) + 5 = 6. Đặt g(E) = 6, h(E), f(E) = g(E) + h(E).
- Thêm D và E vào danh sách mở.
Iteration 3:
- Chọn D (f(D) nhỏ hơn f(C) và f(E)).
- Di chuyển D từ danh sách mở sang danh sách đóng.
- Xem xét các hàng xóm của D: B, E, F.
+ Với F: tentative_g(F) = g(D) + 1 = 4. Đặt g(F) = 4, h(F) = 0, f(F) = g(F) + h(F).
- Thêm F vào danh sách mở.
Iteration 4:
- Chọn F (f(F) nhỏ nhất).
- F là điểm đích, tái tạo và trả về đường đi: A -> B -> D -> F.
Vậy, đường đi ngắn nhất từ A đến F là A -> B -> D -> F.
Dưới đây là một ví dụ chương trình ứng dụng của thuật toán A* với Python:
'''python'''
import heapq
def heuristic(a, b):
return abs(a[0] - b[0]) + abs(a[1] - b[1])
def a_star(graph, start, end):
open_list = []
heapq.heappush(open_list, (0, start))
came_from = {}
g_score = {node: float('inf') for node in graph}
g_score[start] = 0
f_score = {node: float('inf') for node in graph}
f_score[start] = heuristic(start, end)
while open_list:
current = heapq.heappop(open_list)[1]
if current == end:
path = []
while current in came_from:
path.append(current)
current = came_from[current]
path.append(start)
return path[::-1]
for neighbor in graph[current]:
tentative_g_score = g_score[current] + graph[current][neighbor]
if tentative_g_score < g_score[neighbor]:
came_from[neighbor] = current
g_score[neighbor] = tentative_g_score
f_score[neighbor] = g_score[neighbor] + heuristic(neighbor, end)
heapq.heappush(open_list, (f_score[neighbor], neighbor))
return None
# Ví dụ đồ thị (graph) với chi phí giữa các điểm
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'D': 2, 'E': 5},
'C': {'A': 4, 'F': 3},
'D': {'B': 2, 'E': 1},
'E': {'B': 5, 'D': 1, 'F': 1},
'F': {'C': 3, 'E': 1}
}
start = 'A'
end = 'F'
path = a_star(graph, start, end)
print(f"Đường đi ngắn nhất từ {start} đến {end} là: {path}")
```
### Giải thích chương trình:
1. Heuristic function: Hàm heuristic được định nghĩa để tính khoảng cách Manhattan giữa hai điểm.
2. A* function: Hàm `a_star` thực hiện thuật toán A*.
- open_list: Danh sách mở chứa các nút cần được khám phá. Các nút được sắp xếp theo giá trị `f(n)`.
- came_from: Từ điển lưu trữ các nút và nút cha của chúng để tái tạo đường đi ngắn nhất.
- g_score: Từ điển lưu trữ chi phí từ điểm khởi đầu đến mỗi nút.
- f_score: Từ điển lưu trữ giá trị `f(n)` cho mỗi nút.
3. Main loop: Vòng lặp chính khám phá các nút với giá trị `f(n)` nhỏ nhất trước.
4. Reconstruction: Khi điểm đích được tìm thấy, hàm sẽ tái tạo lại đường đi ngắn nhất bằng cách đi ngược từ điểm đích đến điểm khởi đầu thông qua `came_from`.
Chương trình này sẽ in ra đường đi ngắn nhất từ điểm bắt đầu 'A' đến điểm kết thúc 'F'.



![Thuật toán A* tìm đường đi ngắn nhất trong đồ thị [ Cùng học AI ]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjfZQlheasfoPgm8ECN4xfluDdE7zl-3ypag_GCsCjOHijoYNwmEkSfiyJMd3kkQgnq-GWGKlFGxgesWNIEUDQOYXdeqNATJWtDDpfLIvoyCKngDnZ0UvLeFEx31RJzee5v0bGzJDBYrvMxrKoGh4k2c9yeHAt5ceKYnI-t5iHFgUfbcXtbfkMD7ZmUf6Vl/s500/A.png "Thuật toán A* tìm đường đi ngắn nhất trong đồ thị [ Cùng học AI ]")




")



![[C\C++] Cài đặt thuật toán duyệt Đồ thị (DFS, BFS) [Lý thuyết đồ thị]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEilWNCrNUYSyPsAp-6B25x3VPzFtyy-eH909F1m293KAgF6N1oT5tFHZupPEArC9fiaiXd-_W8-wgCahB3Py4m83-wMGqU9tlZKt_p0DI9M-y94epGbcFt4B7giXpLqiMIkttEQOd-TALZF/s1600/duyet+do+thi.jpg "[C\C++] Cài đặt thuật toán duyệt Đồ thị (DFS, BFS) [Lý thuyết đồ thị]")